Architectural Options for Asynchronous Workflow
Duncan Mackenzie
Microsoft Developer Network
December 2001
Summary: This article describes the benefits of asynchronous processing and discusses three possible ways to implement this type of workflow within your own systems. (21 printed pages)
Contents
Introduction
Benefits of Asynchronous Processing
Faster Response Time
Load Balancing
Fault Tolerance
Intermittently Connected Systems
Issues in Asynchronous Systems
Notification or Polling for Status
Time-out Handling
Compensating Logic
Implementation Strategy
Build Your Own Workflow with SQL Server
Use .NET and MSMQ to Handle Workflow
Let BizTalk Handle Workflow for You
Comparing Your Options
Conclusion
Introduction
Many processes that occur as part of a line-of-business application are not executed instantaneously. Authorizing a credit card, for instance, can take ten seconds in some cases. Ten seconds is very fast when you are in line at the local store, but in the world of electronic commerce, ten seconds is a very long time. If your Web site or other application had to sit idle for that length of time, waiting for a customer's credit card authorization, then your ability to handle a large number of concurrent users would be greatly reduced.
Instead, relatively long-running processes, whether they take ten seconds or ten days, should be disconnected from your application and run asynchronously. To run a process asynchronously means that the system making the call does not wait for the request to complete; the request is initiated and the call immediately returns. This type of processing has a large number of benefits, but the primary result is that it disconnects different processes within your system, allowing them to run at different speeds. A set of disconnected, or decoupled systems, allows for the most flexibility in distribution and scaling.
An order processing system, which receives orders from external sources such as Web sites or other companies, is a perfect candidate for the use of asynchronous processing. If such a system is decoupled, the orders will pile up when incoming volumes are high, but the rest of the process does not need to be able to operate at the same speed. The orders can be received as fast as possible by the front end of the system and the rest of the process can catch up during periods of lower volume. The use of an asynchronous connection between the components of the system produces a leveling effect, converting a highly variable input stream into a consistent flow of requests being handled.
It is unlikely that any e-commerce application could function without using asynchronous processing to some degree, so there is little argument against this type of architecture, but it is worthwhile to examine the positive and negative aspects regardless.
Benefits of Asynchronous Processing
Some of the main advantages to an asynchronous architecture include:
- Faster response from the front-end process (usually your Web pages), which is perceived as a faster system by the customer
- Provides an easy way to load balance requests
- Provides fault tolerance
- Allows for intermittently connected systems
Each of these benefits is a result of decoupling the different sections of your application using an asynchronous model. To allow a process to be asynchronous, there must be some form of queue to hold pending requests, and each step of the process communicates with these intermediate queues instead of directly with the previous or next step.

Figure 1. Decouple operations with a queue
Faster Response Time
The first benefit, faster response time, is a result of the customer (whether that is a person using your Web site, or another company's computer system) not having to wait for any amount of order processing to occur. In a synchronous system, the user obtains a response when the entire operation (such as submitting an order) has completed.

Figure 2. Cumulative latency from synchronous operations
In an asynchronous system, when an order is submitted, the customer is delayed for only as long as it takes to send that order off to the next step in the process. In some ways, this faster response time is an illusion because the process has not really completed when the customer receives a response, but they are not kept waiting, which is an important benefit.

Figure 3. Latency is reduced in an asynchronous model
Load Balancing
In a system receiving a high volume of traffic, it is often desirable to spread that load out across multiple servers, and to be able to adjust that distribution as needed to accommodate changes in the number of machines. There are many different ways to handle load balancing in a system, but the infrastructure required by asynchronous processing can make it easy to provide flexible load balancing without any additional software.
In an asynchronous system, I already mentioned that some form of intermediate storage or queue is required to store requests between steps. When an order completes the processing in one step, it is placed into the queue for the next step. When the next step is ready to process another order, it grabs one from this list of pending requests. Implementing load balancing for such a system can be accomplished by just increasing the number of machines processing requests from the pending list for Step B.

Figure 4. Load balancing across a cluster of nodes handling Step B
The use of an intermediate queue results in great flexibility for load balancing and scalability. Any number of machines can be placed on either side of this system, and this flexibility exists for each and every single step. You can fine-tune the performance of your system by using the appropriate amount of hardware for each individual step, or combine steps together to be processed on a single machine.
Fault Tolerance
An asynchronous architecture can make your system fault tolerant, allowing disruptions in the process to occur without taking the entire system down. The same feature that allowed for the flexible load balancing is what provides the fault tolerance as well. If a hardware or software failure removes one of the processing steps, pending requests for that step will just be queued up until the service is restored. There will be no real impact on the previous steps in the process, although the overall processing time will likely be increased by the failure. If the techniques discussed in the preceding section on load balancing have been followed, it is possible that the processing of a step will be merely slowed, not stopped. This same functionality can be provided through the use of clustering, which provides the failover capabilities without doing any load balancing.

Figure 5. Asynchronous system is tolerant of the failure of one or more nodes
In a load-balanced system, the other server(s) processing the same step will continue to take requests off of the queue, and if the servers were already operating near peak capacity, the system performance will decrease.
Note Although the use of request queues provides fault tolerance, the queues themselves become a critical point of failure. The method used to ensure the reliability of these queues is dependent on the specific technology used to implement them, but generally involves failover clustering and writing the messages into a persistent store, such as a database.
Intermittently Connected Systems
The same behavior that makes an asynchronous system fault tolerant also allows these systems to work without having all parts of the workflow connected at all times. In an asynchronous system, one of your workflow stages could be handled by a business partner. The connection between your system and your partner's could be intermittently available or established only on demand. This functionality minimizes the effect of unreliable communication links and allows for more economical system operation by minimizing the use of communication resources.
In an intermittently connected system, a partner could connect and queue up one or more requests into the workflow process, or receive the results of a specific step to then be processed on their systems. Asynchronous processing makes the systems independent of one another; if system A and system B are both connected at the same time, then fine, but if they are not, then their communication will occur without any trouble, as information will be stored until the recipient is available.
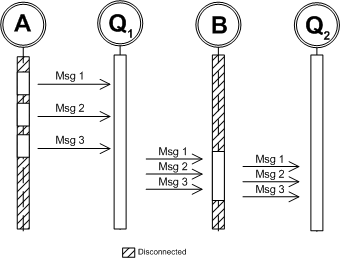
Figure 6. The use of intermediate queues allows for intermittently connected systems without any specialized programming
Intermittently connected systems introduce their own set of architectural decisions, including the frequency of connection, batching of requests between connected periods, and dealing with failed connection attempts. Common scenarios that require this type of system include dealing with an external partner to process payments or to handle order fulfillment, and any situation when a dial-up connection needs to be used instead of a network link. By supporting intermittent connections, systems can also minimize the use of resources that are always available but where the number of connections is limited by licensing, configuration, or system capability limitations—such as databases, FTP servers, and sessions with other back-end systems such as Service Advertising Protocol (SAP).
Issues in Asynchronous Systems
When using asynchronous processing, there are several features that are more difficult to implement than in a synchronous scenario, including:
- Using notification or polling for status tracking
- Handling time-outs
- Creating and executing compensating logic
Notification or Polling for Status
In a synchronous system, the calling process waits for the call to return before it can move on, and although this has negative impact on performance and system responsiveness, it does have some benefits. When the call does complete, it can return along with it some form of status information, such as the success or failure of the process. A simple example to illustrate this issue is the insertion of a new order into a database, obtaining a new database-generated order ID at the same time. Using a synchronous call against the database (possibly through a component, which handles the actual database work), you can send back the order ID immediately, also indicating whether the order was successfully added to the database. In an asynchronous system, the request to insert the order is made, but the actual insertion does not occur at that time, so a database-generated ID cannot be returned at that time and the system does not yet know if the insertion was successful. The two concepts, obtaining the status of a submitted request and the creation of an ID, are closely related as a unique ID is required for any asynchronous form of status tracking.
Generating tracking IDs
There are a variety of ways to obtain a tracking ID when working in an asynchronous system, but the goal of decoupling our systems must be kept in mind when considering these options. An ID can be generated by handling the submission of the request synchronously—obtaining the ID and then passing the request asynchronously into the rest of the process. This solution would reduce the benefits gained by the use of asynchronous processing, though, because it would tightly couple the request submission to at least the first step of request processing.
Alternatively, the system that submits the order could produce the ID, maintaining the asynchronous nature of the system but removing the simplicity of a single location producing unique IDs. To ensure that the IDs being produced by the submitter were unique, two methods are usually used:
- The IDs are generated randomly or semi-randomly, attempting to guarantee uniqueness through the size of the random number space or by creating a number based on a unique hardware component of the system (GUIDs are often used for this purpose)
–or–
- The IDs are unique to a single submitting system, and sent along with an identifier for the submitter, producing a combined unique ID.
I prefer the second idea, as it resembles the general process that has been used (and still is being used) to handle purchase orders (POs) submitted in batches for corporate purchasing and, therefore, translates well when working with existing systems. The submitter, a company in the case of a PO, has their own system for producing unique PO numbers, and they submit that number along with an identifier for their company (could be a customer ID or a system ID). That combination of information is used whenever the submitter needs to determine the status of the specific order. On the receiving end, a unique ID within the order processing system may still be generated and used internally, but the customer's PO number is not removed.

Figure 7. Incoming messages containing reference IDs from the submitting systems
Status tracking
As I just mentioned, you have to have a unique ID to allow for status tracking in an asynchronous system. Well, now that you have that ID, how do you track the status of your requests? Status tracking in an asynchronous system generally takes one of two forms: either a notification to the original caller (a status message sent periodically or upon certain events occurring) or the caller is left responsible to check on the status using some form of polling mechanism. A third possibility, which I will not discuss in detail now, as it is not really suited to an enterprise system, is that the calling system does not require any awareness of the results of its request; it simply sends the request and does not need to know if it succeeds or fails. The two forms of status tracking can be simplistically illustrated by "Hey is my order ready?" versus "Hey, your order is ready." It is all a matter of who initiates the conversation.

Figure 8. Status tracking using notification
Notifications are generally considered the most efficient way to handle status tracking, because information is only sent out when the status of the item has changed, compared to polling, which could result in many unnecessary requests for status.

Figure 9. Status tracking using polling
This is not always the case, though; a system could find an inquiry-based status system more efficient if checking the status of a request was an infrequent action. For the most flexibility, I would recommend implementing both a mechanism that allows status to be requested and status notifications. Consider a Web site that allows you to order products online; after placing the order you can usually go back to the site and view the current status of your order (as often as you want), but that same Web site may be sending you e-mail messages as the order is accepted, processed, and shipped. Both forms of status tracking are useful and both have the same implied requirement on the processing system; the status of every request needs to be tracked.
Time-out Handling
One of the major benefits of asynchronous processing is that you are not waiting on each step to complete, but you are still concerned with how long the entire process takes. To ensure that orders, or whatever form of request you are working with don't end up waiting too long to be processed, you will need a way to specify a maximum amount of time that each asynchronous request is allowed to take. Implementing a time-out mechanism is the only way to prevent orders from lingering in the system for days.
Compensating Logic
Just like the status tracking issue described earlier, compensating logic is most important when something goes wrong. In fact, if you assumed that every request would succeed, that every order would process successfully, your system could be created in a lot less time with a much simpler design. It is dealing with the problems—with the exceptions—that take up the majority of design and implementation time.
Compensating logic is related to the concept of rolling back a transaction in a database—it is the undoing of any actions already completed when the process as a whole fails. In an order processing scenario this might include undoing an inventory reservation when the customer's credit card fails to authorize and the order is canceled as a result. In a synchronous system, there are already technologies provided to handle this issue, including database transactions and the Microsoft Distributed Transaction Coordinator (MS DTC, part of COM+). Under one of these transaction technologies, the programmer can explicitly state that all of the steps of a process are part of a single transaction, and if an error occurs, the services provided by the database or by MS DTC will handle undoing the work done up until the error. In an asynchronous system, it is not possible to use these transaction technologies to manage all of the steps in a process, because the steps are separated by an indeterminate amount of time. You will have to implement your own code to undo any work that has already been done when a process fails. There are a variety of ways to accomplish this, but the generic method is to track/audit the process as it runs, and then use that tracking information to go back and reverse each action. This sounds much simpler than it actually is; the development of compensating logic is a major task.
In the rest of this article, I will explore several different ways of implementing an asynchronous workflow in your own system and illustrate how each different method handles the issues just described.
Implementation Strategy
To illustrate several different options for creating asynchronous workflow, it is helpful to use an example. For the rest of this article, I will be using the example of an order processing system, where an order has to go through a simple four-step workflow, as illustrated in Figure 10.

Figure 10. Simple workflow consisting of four steps
What happens at each stage is not relevant to the discussion of implementation options, but a set of .NET components (with exposed COM interfaces) will be assumed to be available to handle each step.
Note In any real-world system, scalability and reliability are key concerns. Any system where you might "lose" an order now and then (or run the same order through more than once) is not suitable for use, so you have to take care to design your hardware and software systems to guarantee reliability. Scalability is also an issue, especially in public-facing systems, where the potential audience is very large. In all three of the implementation methods described in this article, I will discuss ways to ensure reliability while making the system capable of scaling up as required.
I have broken the choices for implementing the workflow down into three different paths, based on the amount of the implementation you have to create yourself:
- Using Microsoft® SQL™ Server
- Using Microsoft .NET and Microsoft Message Queuing (MSMQ)
- Using Microsoft BizTalk™ Server
The first option describes implementing the solution without relying on any pre-built mechanism designed for the purpose of workflow. In this example, that means using SQL Server to create your own system for queuing and writing your own code to handle the actual movement and processing of the order through the defined workflow. The second option uses the operating system supplied features of MSMQ to implement the queuing of orders as they move through the process, but you still provide your own code to control the movement of the orders from one queue to another and to call into the individual components. Finally, the last option describes the choice of purchasing a system, BizTalk Server, which handles the entire workflow process, leaving you only with the task of defining that workflow in this tool. Of course, in all three cases you will need to implement the components that represent the actual processing occurring at each step of the workflow. It is worth mentioning, though, if the steps consist mainly of transforming, storing, and retrieving messages from various systems, BizTalk can accomplish most of these tasks without any code at all. I will go through each of these options one at a time and explain how the various elements of this order process could be handled within each implementation.
Build Your Own Workflow with SQL Server
Description of solution
To build your own implementation of a workflow system using SQL Server, you have a variety of choices. You could create distinct tables for each state in the workflow (waiting to be authorized, after shipping, etc.) and then "move" the message (an order, for example) from state to state by inserting it into one table and removing it from the other. This would closely resemble how workflow within a queuing system (such as MSMQ, discussed as part of the next implementation) works, but there is little benefit in having SQL Server act like something it is not.
An alternative model involves the use of just a single table for your message and an additional field that is used to hold the current status. Moving a message from one state to another involves just a modification of that status field, and all the messages are always kept in the same location. This is the model that I recommend if SQL is to be used as your workflow engine, creating an additional table to track the date and time that the order entered each step of the process.
Implementation details
An example activity that would fit well into our asynchronous business process concept would be inserting a new order into the database table. After the order has been received, having been submitted through a Web site or from another system, the SQL Server implementation will consist of several key elements: the tables holding the order and associated information, the components to handle the processing of each step, the workflow tracking table, and the program(s) that will coordinate the movement of orders through this process (the controller). Due to the possibly decoupled nature of this system, the controller is not likely to be a single program; it could, in reality, consist of several distinct programs running on various different machines. However it is distributed, the concept of a controller represents all of the workflow-related code and would need to be running for messages to be moved between steps. Using .NET, these controllers could be written as Microsoft Windows® Services that run continuously and handle any pending orders, or as applications that are set up to run at specific times. In a SQL Server-based system, the controller code would follow this basic behavior model:
For a particular step: Query database for the oldest records at this stage (SELECT TOP 1 * FROM Order WHERE Order.CurrentStage = i ORDER BY Order.Date ASC) If order exists then Process record Add entry to Tracking/Auditing table Call Component(s) to process Order If successful Update Tracking table Move Order to next stage (UPDATE Order SET Order.CurrentStage = Order.CurrentStage + 1 WHERE Order.ID = ID) If failure Compensating Logic for all previous steps (i-1 to 1) Update Tracking table
For the best performance and flexibility, separate instances of the controller could be created for each stage, or each stage could be processed on its own thread; either way the controlling code could be separated across machines as desired.
The main benefit of using SQL Server for your workflow is that everything is stored in a database. Having all your orders and their state stored in SQL Server makes checking the current status of an order possible through a simple query, and integration with other systems (which are likely also using a database, perhaps even the same SQL Server) easily accomplished through the use of related tables. Using SQL Server does have its negative points, though: mainly the fact that it is not a workflow engine, but a data store. SQL Server, therefore, does not have any support for many of the features of a workflow system, and you will have to build your own workflow engine that uses it as its data store. Time-outs are an example of a feature that is required in a workflow situation, but is not handled by SQL. To handle a time-out situation, a program (possibly combined with the rest of your workflow logic) would have to periodically scan the table for records older than a certain length of time and handle them as messages that have timed out.
Developing for multiple threads
Another issue when using SQL Server comes into effect when multiple processes are looking for records at the same stage. This is going into more detail than is the intention of this article, but it is important to cover this issue because it serves as a perfect example of the types of issues faced by asynchronous and multithreaded applications. Using the pseudo code provided for the controller process could result in a problem if two or more processes attempt to handle the same stage at the same time. The first process will retrieve the oldest record at a specific stage, and then send that record onto various components to be processed. Only when those components return is the record updated to indicate that it is ready to move on to the next stage. Between the retrieval and that final update, another process might also be processing the same stage, and it would follow the same steps. When the second process retrieves the oldest record at that specific stage, before the first process has performed its update and completed its database transaction, it will retrieve the exact same record as did the first process. That same record will then be sent to the components for the second time, and potentially reprocessed. There are two ways to avoid this problem, the first of which is to use an exclusive table lock on the Order table for the duration of the transaction, which is the only way to prevent the second process from executing a SELECT query against that table until the first process has completed. This will work, but the result is to block all other processes (even on other machines) that use that table for the entire time it takes for the first order to work through the current stage, essentially removing any possibility of parallel processing.
The other option is to modify our process a little to work around this problem—still obtaining an exclusive table lock, but only for a short period of time. Instead of locking the table for the entire time it takes to process the order, you start a transaction, perform your SELECT (including the exclusive table lock) and then update the record to mark it in progress. You can use a variety of methods to mark the record, including setting a Boolean flag or updating to a special status code. Immediately after executing the UPDATE you can commit the transaction, releasing the lock. Work can then continue on that order, and other processes are not blocked for more than the time taken to execute the SELECT and UPDATE. As a stored procedure, this would resemble the following:
CREATE PROCEDURE GetNextOrder @Step int, @OrderID int output, @OrderDate datetime output, @CustomerID int output, @OrderStatus int output, @SubTotal money output, @Tax money output, @ShippingHandling money output, @ShipToName nvarchar(50) output, @ShipToAddressId int output AS DECLARE @NextOrder int SET TRANSACTION ISOLATION LEVEL SERIALIZABLE BEGIN TRANSACTION SELECT TOP 1 @NextOrder = Orders.OrderId, @CustomerID = Orders.CustomerId, @OrderDate = Orders.OrderDate, @OrderStatus = Orders.OrderStatus, @SubTotal = Orders.SubTotal, @Tax = Orders.Tax, @ShippingHandling = Orders.ShippingHandling, @ShipToName = Orders.ShipToName, @ShipToAddressID = Orders.ShipToAddressId FROM [Orders] WHERE [Orders].OrderStatus = @Step ORDER BY [Orders].OrderDate ASC UPDATE Orders SET OrderStatus = OrderStatus + 50 WHERE OrderID = @NextOrder SELECT @OrderID = @NextOrder COMMIT TRANSACTION
SQL Server will execute the steps of this transaction very quickly, so the blocking effect of the table lock will not significantly hurt the performance of the entire system.
Note Although the example given uses polling to look for new orders, it is also possible to use a notification model with SQL Server, but that approach requires a greater amount of "do-it-yourself" plumbing.
Scalability and reliability
A system that uses SQL Server as the workflow engine is made reliable and scalable in the same manner as when SQL Server is used for other purposes. The primary means of handling increased load in a database scenario is to "scale-up," increasing the memory and processor of the machine that is running your database. It is possible to distribute a database across multiple machines for the purposes of distributing load, using such features as federated servers and portioning, to support extremely high loads, but with 8-way and larger machines available, a single machine is often sufficient. To ensure reliability, a failover cluster of 2-4 machines can be used, intended to add nothing to performance, but instead to ensure uptime by providing up to three servers that can take over in the event the live server suffers a major failure. For more information on scalability and reliability in SQL Server 2000, see Federated SQL Server 2000 Servers and SQL Server 2000 Failover Clusters in the SQL Server 2000 SDK.
Use .NET and MSMQ to Handle Workflow
Description of solution
The .NET Framework makes it easy for you to programmatically send and receive messages with Message Queuing (MSMQ), and this solution builds on that basic functionality. Implementing this version of the workflow solution will use a series of queues—one to represent each phase of our workflow, a set of database tables used for storing the final order, and an auditing/tracking table. Similar to the SQL Server implementation just described, this system's key component will be a controller program, written as a Windows Service and designed to handle the workflow-related processing. This program will be responsible for receiving messages from the queues, calling the appropriate component(s) to handle the appropriate processing for each message, and then sending the order into the next queue.
Implementation details
Unlike the SQL Server example, checking for new orders in each stage would not be accomplished through polling, but would instead take advantage of MSMQ's ability to raise events in a listening program such as the controller. Alternatively, a thread could be created for each queue, and a receive process started on each queue with no time-out value specified. The performance difference between these two methods would be very small, but the code would be very different in each case. For detailed auditing and tracking information, you will still need some method to store information, so it is likely that a database table will be required.
The use of MSMQ provides several key benefits, because MSMQ on its own supplies many of the functions required for asynchronous processing. Messages are stored in the queue itself while waiting to be processed, and processing the oldest message first is automatic because message queues are first-in, first-out (FIFO). Messages placed into Message Queues have flexible settings for handling time-outs for delivery into the queue and for time-outs on being received from the queue. Advanced functionality, such as marking certain messages as higher or lower priority, is also provided as a built-in part of MSMQ. Each message, in addition to its main contents (an order, in our example), possesses a variety of properties that provide important auditing details for the message (ArrivedTime, SentTime, SourceMachine, etc). Finally, the programming model for MSMQ is designed with asynchronous workflow in mind, with notification (through events) of the arrival of a new message, avoiding the need to do any polling. The concerns discussed in the SQL Server section regarding locking and concurrency are not an issue with MSMQ; any number of processes can attempt to retrieve a new message off of the same queue at the same time, and MSMQ will ensure that no two processes receive the same message. The number of processes/threads assigned to each stage is completely flexible and can be tuned as the load on the system changes. For more details on MSMQ and examples of programming it from .NET, check out these two related articles on MSDN:
Although MSMQ provides many workflow-related features it, like SQL Server, is still not a workflow engine, and you will be required to code the controlling logic to move messages from stage to stage in your process. MSMQ does provide excellent features for sending and receiving messages, though, which are key components of a workflow solution and components that you would have had to code yourself if building on top of SQL Server.
Scalability and reliability
MSMQ, which is used in this implementation, and as a component of the BizTalk implementation, can also be clustered using Microsoft Cluster Service, providing failover support for the queues on that server. In addition to support for clustering, MSMQ also has an interesting reliability feature that allows it to handle failures that would take down almost any other type of system. When a message is sent to a queue—from your Web site to your back-end MSMQ server, for example—it is an asynchronous operation and it returns right away even if the message has not yet been delivered. If the destination queue, due to a network problem or an unavailable server, cannot be reached, the message is automatically stored on the sending machine (the Web server, in this example) until the destination becomes available. This mechanism, referred to as "store and forward" is often used to allow mobile users to use an application offline, but it also creates a more fault-tolerant system. In a similar situation, using SQL Server or another database as the back end, store and forward would only happen if you built it into your system yourself.
Let BizTalk Handle Workflow for You
Description of solution
The final option that you have to consider is using software designed to help you create a system that uses an asynchronous process. Microsoft BizTalk Server is made to do exactly that, allowing you to design workflow systems and then providing an engine that will take care of running those systems for you. Choosing to write your own workflow system instead of using BizTalk will not likely be a decision based on functionality, as BizTalk can handle almost any workflow's requirements. Instead, it will be determined by the nature of your organization and your method for determining the operating cost of a software system.
Implementation details
BizTalk provides so many features and flexible configuration options that it is difficult to describe any aspect of a BizTalk solution in great detail, but the basic concepts are worth describing. As a product designed specifically for this purpose, BizTalk has support for all the workflow functionality described in this article, including time-outs, tracking, fault tolerance, and more. Although a great deal of your work is done for you, you still have some responsibilities. You need to design and model the workflow process using the BizTalk Orchestration Designer tool.
Figure 11. BizTalk allows you to graphically lay out the workflow of your process—including concurrency, transaction boundaries, actions, and decision points
Each of the actual order processing steps would also be your responsibility to implement, although many steps will be message transformation and validation, which can be handled through the BizTalk configuration. However, BizTalk supports directly calling COM components (or .NET through interoperability), so you would be creating the same components as you would have used in the previous two implementations to handle the actual order processing. Although the processing components are still required, controlling logic (used in both of the previous examples) is not. BizTalk handles all the functionality represented by that aspect of the previous implementations.
Compensation logic is handled by BizTalk in a unique way: You have to create a specially designed workflow that can reverse the actions of your main process, and BizTalk takes care of calling this special workflow when it detects a failure in your system. The real advantages of BizTalk involve its use in a large enterprise-scale system, because it has built-in support for scaling out, scaling up, and providing reliability through clustering across groups of servers, and handles all of the work required to load balance workflow processing across those multiple machines. While writing a workflow system can be a challenging task, getting it to scale is significantly more challenging. Having this work already done for you with BizTalk Server is a key advantage.
Scalability and reliability
BizTalk, the final workflow implementation discussed in this article, has features that allow it to be both scalable and reliable, and all of them are essentially transparent to you as a developer. If you decided to move from a single server to a server farm of 20, using either of the "code-it-yourself" alternatives, you would likely encounter issues that required changes to your code and possibly even your entire design. With BizTalk, the product has been designed to run across multiple machines, so you don't have to worry about it affecting your individual system. You can find detailed information on setting up a very reliable BizTalk implementation in the article on clustering considerations.
Comparing Your Options
Now that I have described several possible ways to implement asynchronous workflow, I will provide some advice on choosing a particular implementation for your system. Each of the solutions has its benefits and its issues, but once you take your requirements and your resources into account, one of the solutions should stand out.
Development complexity
You need to have a system using asynchronous workflow, but do you have the people or the time to build one? Working with any of the implementations described in this article requires design and development resources to create the front end of the system (such as a Web site) and the components that handle each step of the process, but you only need to write your own workflow code if you are going to work with the SQL or MSMQ implementations. This code, which could end up using multiple threads and being installed onto more than one server in your system, requires a high level of development skill to create correctly. Accordingly, if you do not have your own development resources, or if they have limited experience, using a pre-built product may increase your chance of successfully completing your system. The other issue to consider, even if your development team is up to creating the required code, is the time that this development will take. Any system, even one that uses an existing product like BizTalk, requires a great deal of design, development, and testing time, but the expectation is that the time will be reduced if a large portion of the system's functionality is provided for you. So, even if your team could build the system without issue, you must ensure that you have the additional time that this will add to your project.
The use of BizTalk does not come without any design/development cost, though; it can be quite a complex task to set up and configure your first workflow while learning how to use this product. In a single project, one that is relatively simple, the initial set up and learning curve of BizTalk can remove its advantage in time and complexity over a do-it-yourself implementation. This initial hit will reduce the amount of effort required in subsequent projects or when changes are required to the original system.
Total cost of ownership
Depending on how your organization looks at the cost of development resources, you will produce very different calculations for the price of each implementation. BizTalk licensing is per processor, comes in standard and enterprise editions, and also requires your organization to license Microsoft SQL Server. It is quite possible you will already have SQL Server, as it may be used in another part of your system, but you will require another license for each new CPU you run it on (or additional per client or per seat access licenses). The calculation of BizTalk server costs is very dependant on your organization's current systems and the size of the system being designed, but it is just one of the costs you need to consider. Some of the other key areas of expense include the cost of ongoing administration, maintenance, and support. The cost of staff involved in the original design and development process, along with any future modifications to the system, will also have to be considered. All of these elements form part of the overall cost of implementing your system, but when considering the implementations described in this article, your focus will be on the differences between the costs of each method. For example, it is likely that SQL Server will be used (for different tasks) in all three implementations, so the cost of SQL Server can be removed from the comparison. Likewise, the underlying Windows 2000 servers can also be ignored, leaving you with a few critical costs to be determined before a proper comparison can be completed. Licensing, development, support, and administration are the key areas where I recommend focusing your attention, being the highest expense areas that would be affected by your choice of implementation. Now, assuming that the goal is to service the same level of requests with each system, you can start looking at the difference in the cost of each area. I will not attempt to detail these costs, because they will vary widely by the organization and the situation, so you will need to determine the appropriate details as part of your design research. For more information on the costs involved in each of the workflow options presented, you can find pricing information on the Web for SQL Server and BizTalk Server.
Flexibility and organizational personality
Finally, let me add that cost is not the only issue, and that you need to consider what is most appropriate for your company. If you develop most of your systems completely in-house, and you have an adequate size development staff, you may choose to go with a build-it-yourself solution, even though the cost will likely be greater than if using BizTalk. Alternatively, if your organization experiences high turnover in its IT department, and likes the security of running a product that offers technical support and ongoing upgrades, you should go with BizTalk regardless of the cost calculation.
Conclusion
Asynchronous workflow is a powerful architecture that can increase the scalability and reliability of your systems, and it is a great way to work with automated business processes. This article has presented three different ways in which you could add this type of processing to your system, but you have to choose which of these implementations is best suited to your system. What it comes down to is a decision between building and buying. On the build-it-yourself side, though, you also have two choices. Doing everything yourself, and not taking advantage of MSMQ, sounds like the least effective solution, but it places everything into SQL Server and that can make document tracking and integration into the rest of your system extremely easy. Using MSMQ gives you a head start, and brings you a great deal of the asynchronous functionality that is needed to build your solution, leaving you to write the controlling logic to move your messages through the workflow as needed. Finally, using BizTalk you still have to create the components that handle each stage, which is not a requirement you can avoid in any of these solutions, but all of the other workflow elements are provided.
If you have one unchanging workflow running on one server that needs to be implemented, building your own is a very realistic idea. If you wish to support multiple workflows, your workflow is changing relatively frequently, or you need to run a medium to large server group, you would need to duplicate large amounts of BizTalk functionality, likely at a much higher cost than BizTalk itself. A major determining factor is your desire for support, as your own solution will not likely have the level of support that you could obtain on a purchased product like BizTalk. In the end, all three of these solutions are viable means to implementing asynchronous workflow in your application, depending on the specific requirements you have.

Không có nhận xét nào:
Đăng nhận xét