SOA Challenges: Entity Aggregation
Ramkumar Kothandaraman
Microsoft Corporation
May 2004
Applies to:
Microsoft® Visual Studio® .NET
Summary: Use Entity Aggregation (EA), within the larger content of a Service Oriented Architecture (SOA), to integrate duplicate information present in different services in your enterprise that are autonomous in nature—HR, Payroll, and Benefits, for example. (20 printed pages)
Contents
Abstract
Introduction
Entity Aggregation
Entity Aggregation Service
Design Issues
Platform Support
Conclusion
Abstract
Service Oriented Architecture (SOA) is gaining widespread acceptance in the IT industry. It is used predominantly to connect traditionally separate software systems that are autonomous in nature. In its aim to connect disparate and autonomous systems, SOA defines several core design principles: service boundaries are explicit; services share contracts and schema; services use message-based communication for interaction; services are autonomous and managed independently; and services use policy assertions to control the behavior.
Nevertheless, the demand for a robust architecture like SOA, which responds to the demands of businesses to integrate internal or external service systems, is not without its challenges. These challenges make it difficult to realize SOA in an Enterprise. Some of the challenges that must resolved by Technical Architects when integrating systems include identity management, authorization in a distributed environment, Service Aggregation, and Entity Aggregation.
The focus of this document is on Entity Aggregation (EA). Specifically, it looks at the problem context and situations that require integration of information present in different systems. The document goes on to discuss various solution models used to implement an EA solution, and some of the basic design issues that a Technical Architect faces while implementing a solution. Finally, it covers Microsoft technologies that may be used to build an EA solution.
Introduction
As businesses continued to expand over the years, their demand for more IT systems increased. As mergers and acquisitions became the standard, there was an even greater demand for new systems. As a result, today's enterprises are composed of a plethora of IT systems that are independent of each other. The result is hundreds, if not thousands, of application islands.
In this complex environment of systems, there exist silos of application systems. These application systems are self-contained, and therefore do not have an understanding of the world outside of themselves. Business concepts such as Customer and Employee were duplicated in these systems as they evolved independently. For a long time, the existence of independent systems did not give rise to any concerns, since it was typical for individual business units to operate independently of each other and manually coordinate activities between systems. In recent years, however, businesses started making new demands that have resulted in the emergence of a new trend.
This trend, in its movement towards automating business processes between systems, promotes the value of Service Oriented Architecture (SOA). Integrating and aggregating information (entities) that is present in different systems is essential in building solutions that will support this trend. For example, in many businesses employees must make separate phone calls to HR, Payroll, and Benefits to have their addresses updated in the different systems. Through SOA, however, multiple systems are integrated and the entities in the different systems aggregated. By automating these simple processes, employees can now make one phone call or use a self-service portal and update their personal information seamlessly across numerous systems.
Businesses can also reduce total cost of ownership (TCO) by connecting systems with Service Oriented Architecture. Over time, the Enterprise IT group may plan to deliver services directly to end-users by integrating multiple systems. This means that services, offered by applications such as enterprise resource planning (ERP) and customer relationship management (CRM) systems, will be available to end-users, which results in an overall reduction in the TCO for supporting the business functionalities.
SOA promises to continue to stimulate conversation in the IT industry and maintain increasing interest to businesses seeking to lower costs, increase return on investment (ROI), leverage existing assets, and integrate systems. In addition, interest in Entity Aggregation solutions will increase along with the popularity of Service Oriented Architecture.
Adopting a Service Oriented Architecture will not only be a large task for everyone involved, but it will also mean a significant change for organizations. As a result, this task must be properly managed. This is where Entity Aggregation plays a large role.
An Entity Aggregation solution can be designed to not only act as a single point in accessing information that exists in multiple systems, but it also provides a holistic view of an entity and the entity model. Additionally, Entity Aggregation solutions address several design issues to ensure the success of Service Oriented Architecture.
The rest of the paper discusses Entity Aggregation. Section 1 discusses the problem context and scenarios that require integration of information that is present in different systems. Section 2 discusses various solution models that can be used to implement an entity aggregation solution. Section 3 covers some of the key design issues that a solutions architect faces while implementing the solution. Section 4 covers Microsoft technologies that can be used to build an EA solution.
Note In this document, the words services and systems are used interchangeably to represent a business application such as an ERP system. One can think of a business application as a software system that provides business services to Enterprise IT.
Audience
This white paper targets several audiences: IT Architects who own the specification for the enterprise architecture; business process owners who needs to enforce organizational policies at the enterprise level; and Technical Architects who wants to build an EA solution.
Entity Aggregation
There are essentially three reasons for the aggregation of entities in different systems. They include the following:
- Single View of Entity—Having a single "360 degree" view of all common entities spread across enterprise systems provides added value to business users. For example, a unified view of a Customer entity, named Customer Information Repository (CIR), is required to build useful solutions in many enterprises, especially in the banking sector.
- Horizontal Partitions—There are situations where entity information is distributed across many different services, based on factors such as geographical boundaries.
- Cross-Join scenarios—These situations require cross-join among entities present in different services.
The reasons for aggregating entities are discussed below in more detail. Additionally, the purpose and impact of Entity Aggregation are further examined.
Single View of Entity
Information in today's Enterprise IT is essentially "dis-integrated". Very often different systems define business concepts like Customer. For example, a Human Resource Management System (HRMS) application, Payroll application, and Benefits application typically define an Employee entity separately, creating dissonance between systems. As a result, the trend should be towards enforcing consistency between systems by maintaining a holistic view that is concerned with the whole instead of just the parts.1 In the case of building an Employee Self-Service portal, a holistic view, not the bits and pieces, of what constitutes an employee is necessary.
Figure 1 shows a Customer entity defined in an Enterprise Resource Planning (ERP) system and a Customer Relationship Management (CRM) system. At the top of these two systems, solutions such as self-service type applications can be built with a holistic view of the customer.

Figure 1. Unified view of entity
Horizontal Partitions
There are cases where geographical constraints require a partitioning of entries across services. At certain times, however, a solution may require a complete set of information to obtain a detailed picture across services. Figure 2 shows such an example concerning partitions. One can think of stock trades as an entity that is partitioned across various geographical locations.

Figure 2. Entity partitions
Cross Entities Query
Some cases require special handling of entities. In these cases, different services encapsulate related entities, and the solution requires a complicated join between them. Trying to carry out a join-like operation across service boundaries is typically not recommended due to performance degradations. To obtain adequate performance, the related entities need to be brought to a common location—preferably a relationship database management systems (RDBMS) database—where efficient joins can be performed.
Figure 3 illustrates the scenario in the retail industry. The solution involves a join because the inventory system stores the product catalog and the order management system stores order information. The retail solution has a scenario that will help their business analyst decide when stocks need replenishing. The solution will first require an analysis that involves joining data between the order entity and the product catalog entity.

Figure 3. Cross entity query
Entity Aggregation Service
The underlying goal of Entity Aggregation service is to design an Entity Aggregation layer that acts as a single point to access information that may exist in multiple systems. The Entity Aggregation service has the following responsibilities:
- Acts as a unified source of entities.
- Provides a holistic view of an entity.
- Provides a holistic view of the entity model—entities and their relationships with other entities
- Provides location transparency—consumers of the Entity Aggregation layer do not need to know who owns the information.
- Enforces business rules that determine the segments of entities retrieved in a given context.
- Determines the system of record for each data element constituting an entity.
- Enriches the combined data model across systems—the whole being better than the sum of its parts.
To support these responsibilities, an EA Service needs information about entities, such as structure of the entities, services that contain entities, ownership information, and the service's view of the entities. This information can be stored as meta-data. Figure 4 explains Entity Aggregation service:

Figure 4. Entity aggregation service
Solution Models
This section examines possible Solution Models when planning an Entity Aggregation service. The unified view of an entity, provided by the Entity Aggregation service to its consumers, is achieved either by a Straight Through Processing (STP) approach or by a Replication approach.
Straight Through Processing
The Straight Through Processing approach fetches information from appropriate services in real-time, and correlates the information into a single holistic view. This implies that the Entity Aggregation service has real-time connectivity to the services. In addition, the mechanism by which an EA service fetches information about an entity from different services can usually be modeled as an automated process schedule. In this situation, the EA service should be able to associate entities from disparate systems.
Replication
In this mechanism, the EA service replicates the entities. This approach is required when real-time connectivity to services is absent, a complicated join across entities is required, or performance is a key driver to the solution.
This mechanism should provide implementation for replicating entities across service boundaries. It is recommended that a service based replication mechanism be used instead of a database-based replication. Service based replication enables loose coupling between an EA service and legacy services. For example, if the legacy service changes the underlying representation of an entity, it will not affect the EA service since the replication mechanism is established on a service-based approach.
Partial Replication Model
There are situations where it is not necessary to replicate all the information about an entity. For example, there are scenarios where the commonly used attributes are replicated for faster performance, and access to other attributes is completed using STP mechanism.
Limitations of Database Replication
The problem with database-based replication is that both the EA service's and the legacy service's data models should be aligned and tightly coupled. It is not advisable to be dependent on the data-model of the existing legacy service as it may lead to reengineering of the data-model whenever the legacy system is upgraded, rewritten, or replaced with another system. In addition, replication schemes typically do not work well when composing a single record of information from multiple sources.
Design Issues
Several design considerations need addressing when planning an Entity Aggregation service. An Entity Aggregation service should be designed effectively to relate entities it aggregates to query across multiple entities. Other design considerations include the following:
- Schema reconciliation.
- Ownership determination.
- Instance reconciliation.
- CRUD Semantics.
- Life-cycle issues.
Schema Reconciliation
Not only do disparate services have different views of an entity, they may also have their own schematic representation of their views. In order to achieve a single unified view of an entity, it is imperative for the EA service to harmonize the schematic differences between different services. To do this, the EA service should first know how each service represents an entity. Additionally, the EA service should define a holistic view of the entity by logically consolidating the various views. Equally important is for the EA service to discover a way to represent the transformation between a service's view of an entity and the holistic view. The following figure shows the customer information represented in more than one service.

Figure 5. Schema reconciliation
In Figure 5, the EA service creates a consolidated schema containing all the attributes required for a holistic representation of the Customer entity. Both Service1 and Service2 define their own view of Customer entity. EA service also defines mapping between the holistic schema and the views of the individual services.
In the case of the horizontal partitions scenario, schema reconciliation is usually not an issue, as the services share the same schema.
Schema Representation
There are many choices when it comes to entity view representation, including XML-Schema representation, Entity-Relationship Model, and Object Model.
XML-Schema is a popular way to represent an entity, as it is platform neutral. XML-Schema captures the definition of an entity in a very natural way. It also supports the notion of containment types and multi-valued attributes. If XML-Schema is used for entity representation, then extensible style sheet language transformations (XSLT) can be used to represent transformations between two different views.
While XML-Schema is a sound platform-neutral approach for storing the enterprise wide logical model, the individual services may very well be leveraging ER models and Object models to store the respective data.
References
Entity reference refers to the information required to uniquely identify an entity instance. Each service may maintain one or more unique references to an entity instance. References can be thought of as analogous to the primary keys of database tables. In some cases, entities have unique, globally recognized keys, such as a person's social security number or an organization's DUNS number. Be aware that even in cases where unique external identifiers are available for an entity, systems still often use additional internal identifiers to ensure full control over internal data consistency. In expectation of such cases, an EA service should be able to map references that point to a single instance.
Apart from having references held by other services, an EA service can create and hold its own reference for an entity instance. The idea here is for EA service to maintain its own reference (known as master reference) to an entity instance, and map this reference to an individual system reference. Such an undertaking reduces the coupling between an EA service and individual systems, since new systems can be included without affecting EA's reference. At present, many solutions follow this approach.
Master Reference
Entity Aggregation service uniquely identifies an entity instance using a reference known as a master reference. There are two ways to idenfity a master reference:
- It can be a reference held by one of the systems. For example, one can assign a master reference for a Customer entity as a reference held by a CRM system.
- A new master reference can be created by Entity Aggregation service and mapped to other references held by different systems. This is very useful in the case of disconnected scenarios, which is discussed in later sections.
Ownership Determination
It is possible that different services own different fragments of an entity. Consider the case of the Employee entity; the Payroll system owns some attributes of an Employee entity, such as payroll information. Similarly, a Benefit's system owns an employee's benefits information. It is also possible that multiple systems own the same information. For example, attributes such as LastName and FirstName may be represented in more than one system. Moreover, the values of these attributes may not be the same in all instances. In this case, EA service should designate a service as an "authoritative source" for the attributes represented in more than one system.
Having an "authoritative source" has several behavioral implications on Create-Read-Update-Delete (CRUD). For instance, attributes will always be fetched from the authoritative source. If another system represents the same attribute, those values will be ignored by the EA service.
Updates have different semantics. When EA Service receives an update request on an entity, the updates should be propagated to all the owners.
Ownership Precedence
In the case where a value for an attribute is not present in the authoritative source, the value should be fetched from an alternate source. To accommodate this scenario, ownership precedence can be defined where each service is assigned a precedence level—a higher level implying higher precedence.
Ownership Determination for Horizontal Partitioning
In the case of Horizontal Partitioning, entity instances are partitioned according to a predicate based on the number of entity attributes. For example, assume the order entity is horizontally partitioned across two services based on a geographical location, such as New York and London. In this case, the predicate that determines the ownership of the entity instance would look like the following:
Predicate for Service1 = <Location = 'NY'> Predicate for Service2 = <Location = 'London'>
Notation
This section discusses a possible notatational form that can be used to describe various things involved in Entity Aggregation.
Entity Views
Different services have their own views of an entity. It is therefore recommended that an entity view be qualified with the service that defines the view. The following representation can be used to refer to an entity view:
<ServiceName>.<EntityName> Example: CRM.Customer
The ServiceName represents the name of the service, and the EntityName refers to the name of the entity. For example, CRM.Customer represents the CRM system's view of an entity.
Entity View Schema Representation
An entity view is described as a set of attributes. An attribute could be single valued or multi-valued. Take for example an Order entity. It has an attribute called LineItem that is a multi-valued attribute. Additionally, an attribute can be part of a reference. An example follows:
Entity View = <attrib1, attrib2, attrib3> Attribute = attribute name(Single/Multi-valued, Reference) (Default is single) Example: CRM.Customer = <CustID(Ref), LastName, FirstName, TelNos(Multiple)>
Note EA service's holistic view of an entity is a "special" view. Apart from defining the view, EA service should also have information about references that individual services hold on an entity. This could be defined as the following:
Ref<Entity> = { <Service, References> } Example: Ref(Customer) = { <ERP, ERPCustID>, <CRM, CRMCustID> } Instance Reconciliation
To provide a unified view of an entity, EA service needs to correlate an instance of an entity from one service to an instance in another service. A correlation can be produced several ways. For example, a correlation can be achieved by matching entity instances from various services based on some match predicate.
Match Predicate
Match predicate is an expression that maps an instance in one system with an instance in another system. Consider a case where the Customer entity is represented in an ERP and CRM system. The structure of their respective views is shown below:
ERP.Customer = <ERPCustID(Ref), LastName, FirstName, Address, SocSecID, Email addr, ...> CRM.Customer = <CRMCustID(Ref), LastName, FirstName, SSID,...>
Figure 6. Customer entity represented in an ERP and CRM system
Both the ERP system and CRM system use the attributes ERPCustID and CRMCustID uniquely to identify a customer in their systems. If both the ERP and CRM reference contain the same value for all the instances, then the match predicate can be defined as:
<ERP.Customer.ERPCustID = CRM.Customer.CRMCustID>.
However, values for the references may not always be the same. In these cases, some other attributes or combination of attributes can be used to define the match predicate. For example, a Social Security ID can be used to map an instance in the ERP system to an instance in the CRM system. An example of the match predicate appears below:
<ERP.Customer.SocSecID = CRM.Customer.SSID>
The match predicate can be a logical expression that involves more than one field. Also, a one-to-one relationship between the entity instances is a basic requirement for the match predicates to work effectively between systems.
Situations can also arise where it is impossible to come up with a match predicate. For example, there may not be a common field between different views and the systems might not share keys. Manual mapping that employs the pertinent information must be performed in these cases.
Relationship Graph
A graph can represent a set of match predicates. In this graph, services are represented as nodes and the relationship between their respective entity views—expressed as a match predicate—are represented as edges in the graph. Consider an example of an Employee entity represented in three different systems, such as HRMS, Payroll, and Benefits:
HRMS.Employee = <HRMSEmpID(Ref), LastName, FirstName, Address, SocSecID, Position, ...> Payroll.Employee = <EmpID(Ref), LastName, FirstName, SSID, Bank Information ...> Benefits.Employee = <EmpID(Ref), LastName, FirstName, SSID, 401k Info, Medical InsuranceInfo ...> Match predicates Payroll.Employee.SSID = HRMS.Employee.SocSecID Benefits.Employee.EmpID = Payroll.Employee.EmpID
Figure 7. Employee Entity Represented in Three Separate Systems
The same data above is presented in the bi-directional graph below.

Figure 8. Bi-directional graph
A connected bi-directional graph with specific end-points means the correlation was completed automatically, without manual help; If the graph is not fully connected, it means the aggregation cannot be achieved automatically. In this case, human intervention by a professional, such as a Business Analyst or a Database Architect, is necessary to complete the match predicate.
Note Static analysis of the graph will be helpful in figuring out the process involved in fetching information about an entity instance based on attributes.
Identifying Match Predicate
Identification of a match predicate requires an in-depth analysis of the information available in various systems containing the entity information. The use of inferences based on the name of attributes is an unreliable way at arriving at a match predicate, and is therefore not recommended. Until there is standardization of the underlying data (names, prefixes, addresses, etc.), other methods must be used to improve the chances of establishing a viable match predicate.
Usually, success in identifying match predicates can be achieved with a team of IT and Business representatives working towards a solution together. In most cases, individuals such as Business Analysts or Database Architects are the only ones who can reliably arrive at the correct match predicate.
Representing Instance Correlation
To update an entity instance in different systems, an EA service needs the references that each service holds on the entity instance. To perform updates on an entity instance, an EA service may need to explicitly store the reference information.
There are also many cases when the references do not have to be explicitly stored. In the case of an STP solution model where references are shared across multiple systems, it is unnecessary to store the reference information explicitly. Nevertheless, if the solution model is to replicate information, then the EA service has to store the references to the entity instances in a persistent store.
CRUD Semantics
This section discusses Create-Read-Update-Delete (CRUD) semantics from the perspective of an Entity Aggregation service. The CRUD solutions are different for an STP solution model and a replication solution model.
Straight Through Processing
Read
Read request is essentially an attribute-based search. For example, to fetch an entity instance from a legacy system, the caller should provide at least one attribute, such as a reference (key) or a last name. In order to retrieve an entity instance, EA Service should fetch appropriate views of the instance from various services based on the input attributes and aggregate them on the fly. This can be modeled as a scheduled process that contains activities for fetching information from the participating services and aggregating them.
The following example illustrates how this works. This example shows an employee entity represented in an HRMS, Payroll, and Benefits system:
HRMS.Employee = <EmpID(Ref), LastName, FirstName, Address, SocSecID, Position, ...> Payroll.Employee = <EmpID(Ref), LastName, FirstName, SSID, Bank Information ...> Benefits.Employee = <EmpID(Ref), LastName, FirstName, SSID, 401k Info, Medical InsuranceInfo ...> Match predicates Payroll.Employee.EmpID = HRMS.Employee.EmpID Benefits.Employee.EmpID = Payroll.Employee.EmpID
Figure 9. Employee entity in three system sharing the same reference information
From the match predicate in the above case, it can be inferred that all three systems share the same reference information. The process describing how to fetch an employee instance based on an EmpID attribute is described Figure 10.

Figure 10. Read process
Since the references are shared by three systems, the process can simultaneously fetch the information from all the systems. Once the results are fetched, the information retrieved from the three systems is aggregated. The aggregation process involves transforming the results obtained from the legacy systems and mapping it to the holistic view.
There are times when not all the systems share the same references. The following example illustrates this scenario:
HRMS.Employee = <HRMSEmpID(Ref), LastName, FirstName, Address, SocSecID, Position, ...> Payroll.Employee = <EmpID(Ref), LastName, FirstName, SSID, Bank Information ...> Benefits.Employee = <EmpID(Ref), LastName, FirstName, SSID, 401k Info, Medical InsuranceInfo ...> Match predicates Payroll.Employee.SocSecID = HRMS.Employee.SSID Benefits.Employee.EmpID = Payroll.Employee.EmpID
Figure 11. Systems not sharing the same reference
In this example, Payroll and Benefits still share the same references. HRMS maintains its own reference, however. The only way to match an instance from HRMS to Payroll is to use the Social Security ID attribute of both the views. This process is represented in Figure 12:
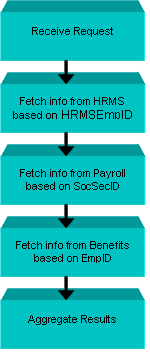
Figure 12. Read process with different match predicate
The process for this search looks very different from the process previously described, where all three systems shared the same reference information. Notice also that the steps in this process are sequential.
Note "Process structure varies based on the search (query) attributes, match predicates, and ownership information."
Auto-Generation of Process
It is possible to generate processes either on the fly or during design using match predicates, relationship graphs, reference attributes, and ownership information.
The pseudo-code below explains one such mechanism that works for a search criteria containing one attribute. It can be modified to work for a search criteria based on multiple attributes. Typically, the Procedure Find takes search criteria as a parameter and returns an instance of the entity in its holistic form.
The first step in this algorithm is finding the authoritative owner for the attribute used in the search criteria. Once the owner is determined, conduct a modified depth first search (DFS) visit on the relationship graph:
EA_DFSVisit(node, searchcriteria, instance of holisticview)
Begin
If node is visited, then return
Fetch information from the service based on the search criteria
Populate the appropriate fields in the holistic view
Node.visited = true
//Execute the following loop in parallel.
For each child node connected to this node
Begin
Find the match predicate along the edge connecting the node
and child node.
Identify the attributes involved in the match predicate.
Form a new search criteria based on these attributes
and the values for the attributes previously fetched.
EA_DFSVisit(childnode, new criteria, holisticview)
end
end
The algorithm can be optimized in certain cases. For example, if all the systems support the attribute used in the search criteria, then information is simply fetched from different systems in parallel. Similar algorithms can be followed to create scheduled processes during the design time.
Update
Updating an entity instance can also be modeled as a scheduled process where each activity in the process sends an update request to the services involved. Like the Read mechanism, there are also several ways to design the Update schedule.
The Update request usually contains two elements: a reference that uniquely identifies the instance, and an update payload that contains information about the updated attributes and their respective values. The structure of the schedule will be different, based on the reference attribute. Like Read mechanisms, it is possible to generate a schedule based on the reference attribute, match predicate, ownership information, and relationship graph.
Compensation
If one of the services fails to handle the Update request, then the EA service should be able to handle this business exception. One of the mechanisms to handle a business exception involves executing a flow that compensates for prior activities.
A Business Analyst usually determines Compensation Logic. Compensation Logic can be either automated or manual. For example, a compensation action may involve alerting the monitoring facility when one of the services returns a business exception, leading to a manual resolution.
Choosing the Services that Require Updating
There are cases when an update request to all services is not required. For example, it is quite possible there are business processes in place to take updated records involving an Employee entity in the HRMS to other systems, such as Payroll and Benefits. In these cases, the EA Service should only send an update request to the HRMS system instead of all three systems. Existing processes involved in updating services must be given careful consideration before introducing new processes. This methodology also applies to create and delete operations.
There are also cases where an update operation requires human intervention. Implementation of an update operation in these cases typically involves both a human workflow and an automated schedule.
Create and Delete
Like an Update request, a Create and Delete request can also be modeled as a scheduled process. The principles of compensation are also relevant in the Create and Delete request processes.
Limitations of Straight Through Processing
The limitations of STP involve searches that return more than one instance. Using STP to return a set of instances is similar to performing a database join between tables, only the join in this case needs to be performed across service boundaries.
The difficulty of implementing an STP solution increases as the join between views becomes more complex. If a solution requires searches that return a set of instances, therefore, consider using a Replication Model instead of an STP Model.
Even when the case involves fetching a single instance, there are situations where STP is inadequate. This situation may occur when a search is based on more than one attribute, and those attributes are owned by different services. Here again, a database join type of operation is required to locate the instance that satisfies the criteria.
Replication Model
In a replication model, an EA service maintains a local copy of the entity instances. This is especially necessary in situations where real-time connectivity to services is absent, high performance is vital to the solution, or when complicated joins across multiple instances of the same entity exist across various services.
Implementation of the Replication Model requires the EA Service to maintain a copy of the entity instances in its holistic form and a copy of the references held by participating services for the entity instances. References are required for synchronization purposes.
Operation Modes
The EA service can be configured to operate in two modes: read-only mode and read-write mode. This configuration is set at an entity level. With certain entities an EA service can operate in a read-only mode, and for other entities it can operate in a read-write mode. Notice the read-write mode is similar to a multi-master scenario.
The EA service's architecture for a replication model is shown in Figure 13. The EA service provides the CRUD service to its consumers. It also has a local storage containing the replica of the entity and the list of references that each service holds for a specific entity instance. A Snapshot processor and synchronization components are used for life-cycle management issues. These issues will be covered in a later section.

Figure 13. Replication model—architecture
The rest of this section examines CRUD semantics for a replication model. Several areas—including life cycle issues, operation issues, and snapshot issues—are examined.
Read Operation
Fetching an entity instance in the replication model is as simple as fetching information about the instance from the local store.
Create
The Create operation creates an instance in the local replica and sends a creation message to a synchronization engine. At a later point in time, references for the newly created entity are updated during the synchronization period.
Note Until all the references are received, it is not possible to perform an Update or Delete operation on an entity instance. It is equally important to know that a Create operation works differently between the read-only mode and the read-write mode.
Creation of a new entity may sometimes be part of the provisioning process. For example, creation of an employee instance may actually be required as part of the process of provisioning a new employee.
Update and Delete
The Update and Delete operations are similar to the Create operations. The Update and Delete operations update and delete appropriate instance from the local replica, and send an update and delete message to a synchronization engine for replica synchronization.
Life Cycle Issues
The life cycle of an entity instance involves two stages, the provisioning phase and the synchronization phase. The provisioning phase deals with issues regarding the setup of entity instances for EA service consumers. The synchronization phase deals with issues regarding synchronization of the replica between EA service and owner services.
Note The Life cycle issues do not manifest themselves in a Straight Through Processing model; rather they pose certain design problems for the replication model. The rest of this section discusses life cycle issues relating to the replication model.
Provisioning
Provisioning happens during two discrete time periods, one of which is the Bootstrapping period. This is when an EA service replica needs to be in accord with the individual service's copy, and when the creation of an entity instance takes place either through an EA service or through individual services.
Bootstrapping
After an entity is configured to use the replication solution model, the EA service should obtain the replica from the owner services. Snapshots can be used to obtain the replica from the owner services. The notion of snapshots is used by database replication components and also applies to service based replication.
Applying Initial Snapshots
Individual services publish snapshots of entity views. The EA service first consumes the published snapshots, then processes them and updates the local replica and references. This process is similar to the traditional extract-transform-load (ETL) mechanisms used in data warehousing environments. Figure 14 illustrates snapshot processing:

Figure 14. Snapshot processing
Snapshot Formats
One of the design considerations for implementing snapshots is choosing the right snapshot format. This is important, especially if the entity has a large number of instances. There are several snapshot format options available:
- XML Infoset—This is a natural format for publishing a snapshot for consumption by other services such as an EA service. Based on the type of encoding mechanism used, however, the size of the snapshot may become very large. As a result, Binary encoding is preferred over XML.
- BCP format—This is a format used by databases for bulk upload. Database formats are not an ideal mechanism for service-based replication, however, since the internal database representation should be transparent to the EA service.
- Custom formats—An example is Comma Separated Format (CSV).
Snapshot Transfer
Once the snapshot has been published, either the EA service can pull the snapshot or the publisher can push the snapshot to the EA service. Different transports can be used, based on parameters such as the size of the snapshot or transport constraints, to name a few examples. A web-service based mechanism can expose snapshots. If the snapshots are very large, however, then FTP may be a viable mechanism for the transport of the snapshots.
Pull based transfers can be implemented by using web services to publish snapshots. In this case, owner service should implement service interfaces for snapshot retrieval.
Snapshot Processing
There are many different ways to perform snapshot processing. For example, the EA service can wait until it receives all snapshots from the different services and then process them all at once. Alternatively, the EA service may choose to process each snapshot as it arrives. The processing of snapshots is very similar to ETL processing techniques applied in data warehousing.
Creation of a New Instance
Creating an employee instance in a system such as an HRMS triggers a process that creates an employee record in different systems. This is typically referred to as a provisioning process. An instance is created, either through the EA service or an individual service.
Instance Created Through EA Service
When an instance is created through the EA service, an update of the local replica takes place and a Create message is sent to the synchronization engine. The synchronization engine is then responsible for propagating the creation message to the owner services.
Instance Created Through Owner Services
There are situations where an instance is created directly in the legacy system. For example, an HRMS user creates an employee record in the HRMS system. The owner service not only keeps track of the created records, but it should also send a business event that contains information about the newly created instance and its reference. Once again, the synchronization engine is responsible for handling the business events generated by the owner service.
In many cases, an instance is provisioned after the EA service receives information about the instance from all owners. This implies that the EA service has references to an entity instance held by each service, and can perform an update and delete operation. There are cases where partially provisioned entities are acceptable, however.
Synchronization
The synchronization engine is responsible for synchronizing the EA's replica with the copy held by the owner services. The synchronization engine interacts with the following components: EA service's CRUD components, local store that contains replica and references, and owner services.
The rest of the section deals with the interaction between the synchronization engine and the different components and mechanisms for processing messages exchanged through interactions.
Interaction between CRUD Components and Synchronization Engine
When CRUD components receive Create/Update/Delete requests (CUD), they update the local store and send a CUD message to the synchronization engine. This interaction is essentially one-way. The implementation involves the sender who queues up the requests, and the receiver who picks up the requests and processes them. Guaranteed delivery between the sender and receiver is required for the interactions between CRUD and the synchronization engine. Figure 15 illustrates the interaction between the CRUD components, synchronization engine, and local storage.
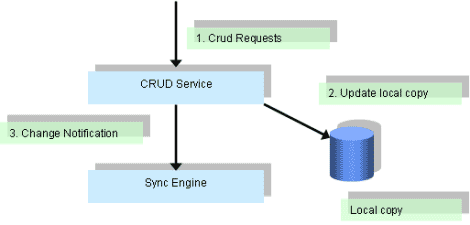
Figure 15. Interaction between CRUD and the synchronization engine
When a CRUD request is received, the CRUD component first determines if the operation mode is read-write. If it is, the CRUD component updates the local copy and queues up the change notification to the synchronization engine. It is recommended that step 2 and step 3 in figure 11 be executed as an atomic transaction. Otherwise, there is the possibility of the change notification not being sent, even when the local copy has already been updated.
Interaction between the Synchronization Engine and the Owner Services
The exchange of change notifications occurs between the synchronization engine and the services that own an entity, to keep the replica in synchronization. The change notifications flow in both directions. For example, when the EA service updates an entity instance, the synchronization engine sends a change notification to the owner services. The services can then update their local store or they can report back with conflicts. Similarly, there are cases when entity instances are updated directly through the services. The services send change notification messages to the synchronization engine.
Updates Originating from EA Service
After receiving a Create notification message from the CRUD component, the synchronization engine determines the Owner services, then transforms a holistic view to the owner's view and sends a create message to the owners. The owners then must respond with information containing a reference to the newly created instance, or a business exception. At this point, the synchronization engine uses the response containing the reference information to update the references map.
Note The synchronization mechanisms differ based on the type of operation being performed, such as create, update, or delete.
The diagram in Figure 16 illustrates the sequence of steps described.

Figure 16. Interaction between the synchronization engine and owner service
The interaction between the synchronization engine and the owner service does not have to be a request-response type of interaction. There are situations where all the messages are asynchronous in nature, and where the response arrives at a different time. For example, consider a situation where the owner service is outsourced and the only way to receive a response is through some sort of batch mechanism. Also, a synchronization engine should support the batch-send mode, where a batch of change notifications can be sent to owner services.
The Update requests are also processed a little differently. After updating the local replica, the CRUD component queues up an Update request to the synchronization engine. There are also many ways to define the structure of an Update request:
- Update request contains the old attribute values and new attribute values for all the attributes.
- Update request contains old attribute and new attribute value for only changed attributes.
- Update request contains changed attributes and version information for the entity instance.
The synchronization engine processes the Update request by identifying the updated attributes and the owners for the attributes. For each owner, the synchronization engine creates an Update request with the appropriate reference for the owner service to identify the entity instance. The owner service then returns with a success, or a failure due to optimistic failure. Notice that standard conflict resolution techniques are used to resolve update conflicts. See Figure 17.

Figure 17. Conflict resolution
Note Processing of Delete requests is very similar to that of Update requests.
Updates Originating from Owner Services
This section discusses the processing of updates that originated from the owner services. In this example, the CRUD operations are performed in the owner service. The EA service is responsible for ensuring the replica is synchronized. There are essentially two mechanisms, push and pull, that can carry out this process.
In the push mechanism, the owner service publishes business events whenever a new entity instance is created, or when an entity instance is updated or deleted. The synchronization engine subscribes to the events published by the owner service and updates its local copy. Unlike the push mechanism, the synchronization engine polls the owner service periodically for updates in the pull mechanism. Also, a time period can be configured through a policy assertion.
Platform Support
SQL Server Distributed Queries Technology
Distributed queries access data from multiple heterogeneous data sources, which can be stored on either the same computers or different computers. Microsoft® SQL Server™ 2000 supports distributed queries by using OLE DB, the Microsoft specification of an application-programming interface (API) for universal data access.
Distributed queries provide SQL Server users with access to distributed data stored in multiple instances of SQL Server, and heterogeneous data stored in various relational and non-relational data sources accessed using an OLE DB provider.
OLE DB providers expose data in tabular objects called rowsets. SQL Server 2000 allows rowsets from OLE DB providers to be referenced in Transact-SQL statements as if they were a SQL Server table. This technology can be used for building a STP solution. The downside to this technology is twofold, however:
- There might be a problem when choosing to evolve the legacy systems independently of other systems, since the Entity Aggregation service should know the internal database schema for the services.
- It allows only straight-through processing. This implies that the legacy systems should always be available.
BizTalk Orchestration
The process of aggregating data using STP involves fetching and correlating data from multiple legacy systems. BizTalk orchestration technology provides a design tool to design this process through visual tools. This "Schedule" is then compiled into a process language called XLANG. BizTalk orchestration also provides a runtime that executes the schedule. There are, however, several limitations to this tool. For instance, only the STP solution model is supported. In addition, this is probably not the modeling tool for aggregating data from multiple services. BizTalk orchestration is process-centric, whereas Entity Aggregation is data-centric.
Data Transformation Services
Microsoft® SQL Server™ Data Transformation Services (DTS) is a set of graphical tools and programmable objects that lets you extract, transform, and consolidate data from disparate sources into single or multiple destinations.
DTS can be used in both STP as well as replication solution models. In the STP model, DTS can be used during the provisioning phase to match instances in different services and upload the reference mapping table in the EA service.
In the replication solution model, DTS can be used during the provisioning phase to apply the initial snapshot and update the reference mapping table.
Conclusion
Entity Aggregation is one of the major issues architects face when it comes to implementing SOA in their enterprise. In this white paper, we introduced the concept of Entity Aggregation, the scenarios that require Entity Aggregation, and different solution models that can be used to implement an Entity Aggregation solution. We also discussed various design issues involved in implementing Entity Aggregation, and methods to tackle those issues.
Contributors
John deVadoss, Chris Keyser, Maarten Mullender (Microsoft Corporation)
E.G.Nadhan (EDS)
1 Sometimes, the term canonical schema is used instead of holistic view. This term, however, is not entirely accurate, as canonical schema implies that all the services (including EA service) share the same schema, which need not be the case.
2 Eager replication keeps all replicas exactly synchronized at all nodes where as lazy replication uses asynchronous messages to propagate updates to nodes containing replica.

Không có nhận xét nào:
Đăng nhận xét